
Análisis de Sensibilidad e Incertidumbre en Modelos Computacionales Complejos
1. Introducción y Definiciones
En el modelado computacional de fenómenos físicos complejos las entradas del modelo rara vez se conocen con precisión absoluta. Esto hace necesario implementar procedimientos sistemáticos para evaluar la fiabilidad de las predicciones.
Distinción Clave
- Análisis de Incertidumbre (UA): Es la cuantificación de los límites dentro de los cuales se espera que se encuentre la realidad. Implica estimar las funciones de distribución de las consecuencias resultantes de la variación colectiva de los parámetros de entrada. Se centra en la pregunta: «¿Cuánto varía la salida Y cuando varían las entradas X?»
- Análisis de Sensibilidad (SA): Examina las relaciones entre los cambios en los parámetros del modelo y las consecuencias. Su objetivo es clasificar («rankear») los parámetros según su importancia relativa en la variación de la salida. Se centra en la pregunta: «¿Qué parámetros X son los responsables de la variación en Y?»
2. Metodología General
El proceso estándar para realizar estos análisis consta de los siguientes pasos secuenciales
-
Identificación de parámetros: Seleccionar qué parámetros del modelo contribuyen a la incertidumbre.
-
Caracterización: Definir rangos, distribuciones de probabilidad (Normal, Lognormal, Uniforme, Beta, Triangular, etc.) y correlaciones entre parámetros.
-
Muestreo: Generar vectores de entrada utilizando un esquema estratificado (ver sección LHS).
-
Ejecución del Modelo: Correr el código computacional con los valores muestreados.
-
Estimación de Distribuciones: Generar funciones de distribución acumulativa complementaria (CCFDs) y bandas de confianza.
-
Ranking de Importancia: Calcular medidas de sensibilidad (PCC, SRC) para identificar los parámetros dominantes.
3. Técnicas de Muestreo: Latin Hypercube Sampling (LHS)
Para que un análisis sea eficiente computacionalmente, el esquema de muestreo debe cubrir el espacio de parámetros adecuadamente con el menor número de ejecuciones posible.
Comparación: Monte Carlo vs. LHS
-
Muestreo Aleatorio Simple (Monte Carlo): Selecciona valores aleatoriamente basándose en la densidad de probabilidad. Puede dejar huecos en el rango de parámetros o agrupar muestras por azar.
-
Latin Hypercube Sampling (LHS): Es un muestreo aleatorio estratificado. El rango de cada variable
 se divide en
se divide en  intervalos de igual probabilidad. Se selecciona un valor aleatorio dentro de cada intervalo. Estos valores se emparejan aleatoriamente (o mediante emparejamiento restringido) para formar los vectores de entrada
intervalos de igual probabilidad. Se selecciona un valor aleatorio dentro de cada intervalo. Estos valores se emparejan aleatoriamente (o mediante emparejamiento restringido) para formar los vectores de entrada
Ventaja del LHS: Fuerza a que el valor de cada parámetro se extienda a través de todo su rango, lo que permite estimaciones más precisas con tamaños de muestra más pequeños (
Control de Correlaciones
En el muestreo LHS, el emparejamiento aleatorio de variables puede crear correlaciones «espurias» no deseadas. Para evitar esto, se utiliza la técnica de Iman/Conover, que restringe el emparejamiento para mantener las correlaciones de rango por pares cercanas a cero, o para inducir una estructura de correlación de rango deseada definida por el usuario.

4. Medidas de Sensibilidad
Una vez ejecutado el modelo, se utilizan técnicas de regresión para correlacionar las entradas ( ) con las salidas (
) con las salidas ( ).
).
Coeficientes de Regresión Estandarizados (SRC)
Se construye un modelo de regresión aproximado de la forma:
![\[Y^* = \sum_{j=1}^{k} b_j^* x_j^*\]](https://upgimi.com/wp-content/ql-cache/quicklatex.com-249211c3df70a7734cf112856fcfa127_l3.png "Rendered by QuickLaTeX.com")
Donde las variables han sido estandarizadas (media 0, varianza 1). Los coeficientes  (SRCs) proporcionan una medida directa de la importancia relativa de los parámetros de entrada, ya que no están influenciados por las unidades de medida (metros, kilogramos, etc.).
(SRCs) proporcionan una medida directa de la importancia relativa de los parámetros de entrada, ya que no están influenciados por las unidades de medida (metros, kilogramos, etc.).
Coeficientes de Correlación Parcial (PCC)
El PCC mide la relación lineal única entre una entrada  y la salida , eliminando los efectos lineales de todas las demás variables. Se calcula analizando la correlación entre los residuos de y los residuos de después de realizar regresiones sobre las demás variables.
y la salida , eliminando los efectos lineales de todas las demás variables. Se calcula analizando la correlación entre los residuos de y los residuos de después de realizar regresiones sobre las demás variables.
Transformación de Rangos (PRCC y SRRC)
Si la relación entre entradas y salidas es no lineal, los coeficientes calculados sobre los datos brutos (RAW) pueden ser engañosos. En su lugar, se utilizan los rangos de los datos (el valor más pequeño tiene rango 1, el siguiente 2, etc.).
-
SRRC: Standardized Rank Regression Coefficients.
-
PRCC: Partial Rank Correlation Coefficients.
El uso de rangos suele ser más revelador en modelos complejos, ya que linealiza relaciones monótonas no lineales10.
Coeficiente de Determinación ( )
)
Indica qué porcentaje de la variación total de la salida es explicado por el modelo de regresión de las entradas . Cuanto más cercano a 1, mejor es el ajuste del análisis de sensibilidad.

6. Conclusiones
-
Eficiencia: El uso de LHS permite explorar el espacio de parámetros multidimensional de manera mucho más eficiente que el muestreo aleatorio simple.
-
Robustez: La transformación de rangos (PRCC/SRRC) es esencial cuando se analizan modelos físicos con comportamientos no lineales.
-
Interpretación: Mientras que los SRC indican la importancia relativa para la construcción del modelo de regresión, los PCC miden la contribución única de una variable. Ambos son complementarios para diagnosticar la importancia de los parámetros.
ARTÍCULO
Análisis Integral de Sensibilidad e Incertidumbre en Modelos Matemáticos: Fundamentos, Metodologías y Aplicaciones
Autor: José Enrique Martín García
Resumen Ejecutivo
Los modelos matemáticos son simplificaciones de la realidad utilizadas para predecir comportamientos, probar hipótesis y fundamentar la toma de decisiones. Sin embargo, la utilidad de un modelo está intrínsecamente limitada por las incertidumbres en sus parámetros de entrada, su estructura y sus condiciones de contorno. El Análisis de Incertidumbre (UA) busca cuantificar la variabilidad en las salidas del modelo debido a estas entradas inciertas, mientras que el Análisis de Sensibilidad (SA) investiga cómo esta variabilidad de salida puede asignarse a las diferentes fuentes de incertidumbre en la entrada. Este artículo proporciona una revisión exhaustiva de los fundamentos teóricos, la distinción crítica entre incertidumbre aleatoria y epistémica, y las metodologías principales, abarcando desde técnicas locales basadas en derivadas hasta métodos globales avanzados basados en la descomposición de la varianza (índices de Sobol’).
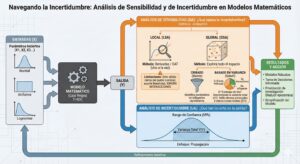
1. Introducción: El Desafío de la Modelización
Un modelo matemático puede representarse abstractamente como una función  , donde es la salida (o vector de salidas) de interés, y
, donde es la salida (o vector de salidas) de interés, y  es el vector de factores de entrada. Estos factores pueden ser parámetros físicos, condiciones iniciales, forzamientos externos o incluso variables que definen la estructura del modelo.
es el vector de factores de entrada. Estos factores pueden ser parámetros físicos, condiciones iniciales, forzamientos externos o incluso variables que definen la estructura del modelo.
En un mundo ideal, conoceríamos los valores exactos de , y el modelo, si fuera perfecto, predeciría con exactitud. En la realidad, casi nunca se conoce con precisión; los valores están sujetos a incertidumbre. En consecuencia, la salida no es un valor determinista, sino una variable aleatoria con su propia distribución de probabilidad.
El estudio riguroso de este fenómeno se divide en dos campos interconectados pero distintos:
-
Análisis de Incertidumbre (UA – Uncertainty Analysis): Se centra en la propagación de la incertidumbre. Si describimos las entradas
con distribuciones de probabilidad, el UA busca determinar la distribución de probabilidad resultante de la salida . Responde a la pregunta: «¿Qué tan incierta es mi predicción?». -
Análisis de Sensibilidad (SA – Sensitivity Analysis): Se centra en la atribución de la incertidumbre. Estudia cómo la variación en la salida
puede repartirse, cualitativa o cuantitativamente, a las variaciones de las diferentes entradas  . Responde a las preguntas: «¿Qué factor es el mayor responsable de la incertidumbre en ?» y «¿Qué factores son irrelevantes?».
. Responde a las preguntas: «¿Qué factor es el mayor responsable de la incertidumbre en ?» y «¿Qué factores son irrelevantes?».
La realización de UA y SA no es un paso opcional; es un prerrequisito para la calibración del modelo, la validación, la reducción del modelo y la toma de decisiones robusta bajo riesgo.
2. Taxonomía de la Incertidumbre
Para realizar un análisis efectivo, primero debemos entender la naturaleza de la incertidumbre que enfrentamos. En la literatura académica, se distingue fundamentalmente entre dos tipos:
2.1. Incertidumbre Aleatoria (Estocástica o Irreducible)
Se refiere a la variabilidad intrínseca o aleatoriedad inherente en el sistema físico que se está modelando. No se puede reducir aumentando el conocimiento o la cantidad de datos.
-
Ejemplos: La desintegración radiactiva de un átomo específico, la fluctuación instantánea del viento, la variabilidad genética exacta entre individuos.
-
Tratamiento: Se modela utilizando distribuciones de probabilidad que reflejan la frecuencia observada de los eventos.
2.2. Incertidumbre Epistémica (Subjetiva o Reducible)
Surge de la falta de conocimiento sobre el sistema. Teóricamente, podría reducirse si se recopilaran más datos, se realizaran mejores experimentos o se mejorara la física del modelo.
-
Ejemplos: Un coeficiente de fricción mal medido, desconocimiento de las condiciones iniciales exactas de un contaminante en un río, o el uso de una ecuación lineal para aproximar un fenómeno no lineal (incertidumbre estructural del modelo).
-
Tratamiento: Se modela utilizando distribuciones de probabilidad que reflejan el «grado de creencia» del experto sobre los valores posibles del parámetro (enfoque bayesiano), o mediante intervalos.
En la práctica, muchos análisis de sensibilidad modernos tratan ambos tipos de incertidumbre conjuntamente mediante un marco probabilístico unificado, asignando Funciones de Densidad de Probabilidad (PDF) a todos los parámetros inciertos.
3. Análisis de Incertidumbre: Propagación
El objetivo del UA es mapear el espacio de probabilidad de entrada al espacio de probabilidad de salida.
3.1. Métodos Analíticos (Aproximación de Taylor)
Para modelos simples y casi lineales, se puede aproximar la varianza de la salida utilizando una expansión en serie de Taylor de primer orden alrededor de un punto nominal. Si las entradas son independientes, la varianza de es aproximadamente:

-
Limitaciones: Altamente inexacto para modelos no lineales o con grandes incertidumbres de entrada.
3.2. Métodos de Muestreo (Simulación de Monte Carlo)
Es el estándar de oro para modelos complejos y no lineales.
-
Definición: Se asignan distribuciones de probabilidad (PDFs) a cada entrada
. -
Muestreo: Se generan
 conjuntos de vectores de entrada aleatorios
conjuntos de vectores de entrada aleatorios  muestreando de estas distribuciones.
muestreando de estas distribuciones. -
Simulación: Se ejecuta el modelo
veces, una para cada vector de entrada, obteniendo valores de salida  .
. -
Análisis: El conjunto de salidas
se utiliza para construir empíricamente la PDF de la salida y calcular estadísticas como la media, la varianza y los intervalos de confianza (percentiles 5% y 95%).
El desafío del método de Monte Carlo es su costo computacional. Para obtener estimaciones precisas de las colas de la distribución, puede necesitar ser del orden de  a
a  , lo cual es inviable si una sola ejecución del modelo toma horas o días. Esto lleva al uso de técnicas de muestreo más eficientes (como el Hipercubo Latino – LHS) o al uso de metamodelos.
, lo cual es inviable si una sola ejecución del modelo toma horas o días. Esto lleva al uso de técnicas de muestreo más eficientes (como el Hipercubo Latino – LHS) o al uso de metamodelos.
4. Análisis de Sensibilidad: Clasificación y Metodologías
El Análisis de Sensibilidad es el núcleo de la comprensión del modelo. Se clasifica generalmente en dos grandes categorías: Local y Global.
4.1. Análisis de Sensibilidad Local (LSA)
El LSA estudia el impacto de pequeñas perturbaciones en las entradas alrededor de un punto de referencia nominal  . Es esencialmente un estudio de gradientes.
. Es esencialmente un estudio de gradientes.
-
Fundamento Matemático: La medida de sensibilidad es la derivada parcial
 evaluada en .
evaluada en . -
Método «Uno a la Vez» (OAT – One-at-a-Time): Se varía un parámetro
una pequeña cantidad  manteniendo los demás fijos, y se observa el cambio
manteniendo los demás fijos, y se observa el cambio  . El índice de sensibilidad es
. El índice de sensibilidad es  (normalizado para comparar parámetros con diferentes unidades).
(normalizado para comparar parámetros con diferentes unidades). -
Ventajas: Computacionalmente barato y fácil de interpretar.
-
Desventajas Críticas:
-
Solo es válido en la vecindad inmediata del punto nominal.
-
Asume linealidad del modelo.
-
Ignora las interacciones entre parámetros: No puede detectar si el efecto de
 depende del valor que tome
depende del valor que tome  .
.
-
En la modelización moderna de sistemas complejos, el LSA se considera a menudo insuficiente y potencialmente engañoso.
4.2. Análisis de Sensibilidad Global (GSA)
El GSA supera las limitaciones del LSA explorando todo el espacio factible de los parámetros de entrada simultáneamente. Evalúa cómo la incertidumbre total de la salida se ve afectada por la incertidumbre de las entradas a lo largo de todo su rango de variación posible, incluyendo interacciones y no linealidades.
4.2.1. Métodos de Cribado (Screening Methods): El Método de Morris
Cuando un modelo tiene decenas o cientos de parámetros, un GSA completo es demasiado costoso. Los métodos de cribado actúan como un «triaje» para identificar rápidamente qué parámetros son despreciables y cuáles son importantes.
-
Concepto: El método de Morris («Elementary Effects») es un híbrido eficiente. Realiza múltiples análisis OAT aleatorizados a lo largo de una cuadrícula que cubre el espacio de parámetros.
-
Resultados: Para cada parámetro
, calcula dos estadísticas:-
 (media absoluta de los efectos elementales): Indica la importancia global del parámetro.
(media absoluta de los efectos elementales): Indica la importancia global del parámetro. -
 (desviación estándar de los efectos elementales): Indica la presencia de no linealidades o interacciones. Si es alto, el efecto del parámetro cambia dependiendo de dónde se encuentre en el espacio, lo que implica interacción con otros factores.
(desviación estándar de los efectos elementales): Indica la presencia de no linealidades o interacciones. Si es alto, el efecto del parámetro cambia dependiendo de dónde se encuentre en el espacio, lo que implica interacción con otros factores.
-
4.2.2. Métodos Basados en la Varianza: Índices de Sobol’
Actualmente, se consideran el «estándar de oro» para el GSA. Se basan en la descomposición de la varianza total de la salida del modelo  .
.
Si  y las entradas son independientes, la varianza total se puede descomponer en términos de varianzas parciales:
y las entradas son independientes, la varianza total se puede descomponer en términos de varianzas parciales:

Donde  es la varianza de la expectativa condicional
es la varianza de la expectativa condicional ![V(E[Y|X_i])](https://upgimi.com/wp-content/ql-cache/quicklatex.com-d8a1ef3ece0ea1d0d458369a3deb5a2f_l3.png "Rendered by QuickLaTeX.com") . Conceptualmente, mide cuánto se reduciría la varianza total de si pudiéramos fijar el valor exacto de .
. Conceptualmente, mide cuánto se reduciría la varianza total de si pudiéramos fijar el valor exacto de .
Se definen dos índices principales:
- Índice de Sensibilidad de Primer Orden (
 ):
): Representa la fracción de la varianza total de salida debida únicamente al efecto principal del parámetro , sin considerar interacciones.
Representa la fracción de la varianza total de salida debida únicamente al efecto principal del parámetro , sin considerar interacciones. - Índice de Sensibilidad Total (
 ):
):![S_{Ti} = \frac{E[V(Y|X_{\sim i})]}{V(Y)} = 1 - \frac{V(E[Y|X_{\sim i}])}{V(Y)}](https://upgimi.com/wp-content/ql-cache/quicklatex.com-ad07bc331be09aa3709e1525f2c286c2_l3.png "Rendered by QuickLaTeX.com") (Donde
(Donde  indica todos los parámetros excepto ).Representa la fracción de la varianza total debida a incluyendo todas sus interacciones con cualquier otro parámetro.
indica todos los parámetros excepto ).Representa la fracción de la varianza total debida a incluyendo todas sus interacciones con cualquier otro parámetro.
Interpretación:
-
Si
 , el parámetro es no influyente y puede fijarse a cualquier valor dentro de su rango sin afectar la varianza de salida (útil para la reducción del modelo).
, el parámetro es no influyente y puede fijarse a cualquier valor dentro de su rango sin afectar la varianza de salida (útil para la reducción del modelo). -
La diferencia
 cuantifica el grado de interacción de con otros parámetros. Un modelo es puramente aditivo (sin interacciones) si
cuantifica el grado de interacción de con otros parámetros. Un modelo es puramente aditivo (sin interacciones) si  .
.
4.3. Metamodelos (Surrogate Models)
Dado que los métodos basados en varianza (Sobol’) requieren miles de ejecuciones del modelo, a menudo es inviable aplicarlos directamente a modelos computacionales pesados (ej. Dinámica de Fluidos Computacional – CFD).
La solución es construir un metamodelo (o modelo sustituto). Es una aproximación matemática rápida (como una regresión polinómica, procesos gaussianos o redes neuronales) entrenada con un número limitado de ejecuciones del modelo original. Una vez validado, el GSA se realiza sobre el metamodelo rápido en lugar del modelo original lento. Una técnica popular en este contexto es el uso de Expansiones de Caos Polinomial (PCE), que proporcionan los índices de Sobol’ casi analíticamente como parte de su construcción.
5. Flujo de Trabajo Recomendado
Para un análisis riguroso en un entorno de investigación o ingeniería avanzada, se sugiere el siguiente flujo de trabajo:
-
Definición del Objetivo: ¿Qué salida
es crítica? ¿Cuál es el propósito del análisis (calibración, simplificación, evaluación de riesgos)? -
Caracterización de la Incertidumbre de Entrada: Este es el paso más difícil y crucial. Se deben definir PDFs para todos los parámetros
basándose en datos experimentales, literatura o juicio de expertos. Definir rangos y formas (Uniforme, Normal, Lognormal, Beta, etc.). -
Cribado (Opcional pero recomendado): Si
 , aplicar el método de Morris para eliminar parámetros irrelevantes y reducir la dimensionalidad del problema.
, aplicar el método de Morris para eliminar parámetros irrelevantes y reducir la dimensionalidad del problema. -
Análisis de Incertidumbre (Propagación): Usar muestreo de Hipercubo Latino (LHS) y Monte Carlo para generar la PDF de la salida. Evaluar los intervalos de confianza de la predicción.
-
Análisis de Sensibilidad Global (Sobol’): Calcular los índices
y para los parámetros importantes restantes. Si el costo es prohibitivo, considerar un metamodelo (PCE o Procesos Gaussianos). -
Interpretación y Acción: Usar
para identificar dónde enfocar los esfuerzos de investigación para reducir la incertidumbre epistémica. Usar parámetros con para simplificar el modelo.
6. Conclusiones
El análisis de sensibilidad y de incertidumbre transforma el modelado matemático de un ejercicio de producción de números deterministas a una herramienta robusta para comprender sistemas complejos bajo condiciones de información incompleta.
Ignorar la incertidumbre o confiar únicamente en análisis de sensibilidad locales (OAT) en modelos no lineales puede llevar a una falsa confianza en las predicciones y a decisiones erróneas. La adopción de métodos globales (GSA), aunque computacionalmente más exigente, proporciona el único mapa verdadero de cómo las incertidumbres de entrada gobiernan el comportamiento del modelo, permitiendo identificar tanto los factores dominantes como las interacciones ocultas que a menudo impulsan el comportamiento del sistema. En la ciencia e ingeniería modernas, la credibilidad de un modelo depende cada vez más de la calidad de su análisis de sensibilidad e incertidumbre asociado.